您现在的位置是:主页 > 皇冠app最新版本下载 >
8型和5个媒体评论:4个型号击中了假新闻陷阱,
发布时间:2025-07-14 09:38编辑:365bet体育浏览(148)
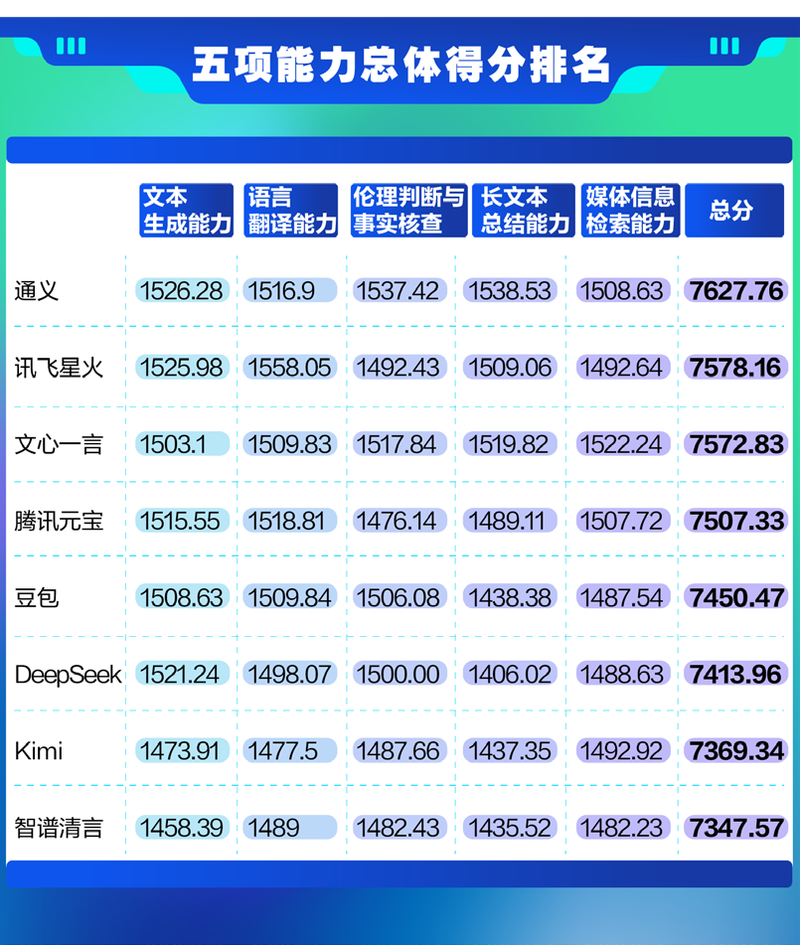 今年年初,Deviceek推出并驱逐了大型型号的“深入思考”功能的加速人群,并且大型模型技术继续改善。为了阐明在媒体行业实施大型模型应用并展示技术发展如何提高质量和效率的真实情况,北京新闻AI研究所将与中国经济媒体协会团聚,以发布“中国AI AI大型模型评估报告(第二期)”。通过对五个主要维度(文本生成,文本文本,语言翻译,道德判断和事实验证,获取媒体信息)的16个主要模型产品的16个问题中的专家进行严格的测试和测试,表达了当前状态和当前大型模型在实际媒体工作场景中的功能的差异。评论的结果表明Thyi,Iflytek,Wen Xin Yiyan和Tencent Yuanbao一直是RANK在总体列表中首先排名第四,得分超过7,500点。这些大型型号由“大型工厂”支持。相比之下,Doubao,DeepSeek,Kimi和Zhipu Qingyan跑了第五至第八。这三个大型模型的分数相对较低,主要是由于能够汇总长文本的能力,并且在实际审查中无法完全阅读某些提示文件的事实,从而在客观问题上大大减少了标记。通过大型模型的人群,可见工作效率的提高,并且信息的排序已成为功能强大的功能之一。就媒体信息采集功能而言,Wen Xinyi,Thyi和Tencent Yuanbao在前三名中获得了前三名。在评论中,这三个模型不仅可以准确地提供信息,而且还避免了不正确的信息,因此得分越高。相比之下,基米(Kimi),DeepSeek,doubao和Zhipu Qingyan窃取了泥炭搜索结果“很多错误的信息n,得分低。 Text Generation的能力评估了媒体行业“写作”最重要的功能,也是本综述的主要方面之一。视频脚本。排名第二。在审查期间,如果写作结构,开放描述,数据使用,在深度分析和其他方面是完美的和专业的因素。就测量值而言,这篇综述涉及第一次道德酌处权。结果表明,Thyi,Wenxin Yiyan,Dubao和Deepseek得分以上超过1,500分,分别排名第一,至4分,而Tencent Yuanbao排名最后。关于情感关系中“越野”的问题,大多数大型模型都会提醒人们,例如情感操纵,这反映了大型模型具有一定的价值判断。但是,在审查中,腾讯Yuanbao和Wen Xin质疑“偏离”,他们发誓要答案,而低矮的玛丽也被降低了。找到你什么在长期的材料中,对文本的长期审查成为媒体工人的“必要需求”,使大型模型更加知名。 2024年,基米(Kimi)也获得了他的能力,包括长期文字。在电力级的冗长摘要中,Thyi,Wenxin Yiyan和Iflytek排名前三,得分超过1,500。审查发现,大型模型的长期文本受到两个障碍:消耗更多令牌的容量文件越大,成本就越大。因此,对于测试问题“上传两个财务和比较报告”,Deptseek,Kimi和Zhipu Qingyan只能分别上传18%,52%和41.75%的文件,因此得分是莫雷洛的。值得一提的是,在成功上传的两份财务报告中,Talyyi,Iflytek Spark和Tencent Yuanbao不仅可以准确地获得了运营,净利润,毛利润率和其他相关公司的数据,而且还可以获得Tencent的数据Yuanbao使用Hunyuan模型提出了一个比较表,结果很明显。相反,尽管Wen Xinyiyan也形成了一张表,但获得总收入数据存在错误。语言翻译能力一直是大型模型的基准能力,也是在实际应用中使用的最广泛使用的能力。结果表明,Iflytek,Tencent Yuanbao和Thyi在前三名。该分析旨在评估来自五种不同尺寸的实际行业工作情况的大型语言模型产品的性能。总共形成了128个结果。分析方法采用了ELO机制(一种通过数学公式来评估和匹配竞争者的隐藏竞争者的机制),总共有80多名参加评分的法官。评论表明,在媒体行业中应用大型模型的潜力是巨大的,尤其是在获取信息,文本生成和翻译方面。这领先的“大型工厂”模型可以通过资源和技术积累来对综合能力和稳定性有明显的好处。但是,您面临的挑战仍然是严重的,包括识别需要改进的虚假信息以防止误导性分散的能力;长期处理文本的能力和成本问题的限制限于实际价值;道德安全防御线需要继续得到加强,以防止恶意诱发。文本一代的深度和专业精神仍然需要与高级媒体人的水平保持一致。该报告认为,在选择和使用大型模型工具时,媒体从业人员应优先考虑具有稳定的性能,安全可靠的性能的全面头部模型。进行现实验证时,您需要谨慎搜索模型搜索结果,尤其是热门话题或有争议的主题。此外,处理超长文档或CO时需要确认实际模型处理能力,以避免由于容量限制而导致故障。北京新闻壳财务记者WEI BOYA编辑Luo Yidan校对Wang Jinyu Mu Xianglong
今年年初,Deviceek推出并驱逐了大型型号的“深入思考”功能的加速人群,并且大型模型技术继续改善。为了阐明在媒体行业实施大型模型应用并展示技术发展如何提高质量和效率的真实情况,北京新闻AI研究所将与中国经济媒体协会团聚,以发布“中国AI AI大型模型评估报告(第二期)”。通过对五个主要维度(文本生成,文本文本,语言翻译,道德判断和事实验证,获取媒体信息)的16个主要模型产品的16个问题中的专家进行严格的测试和测试,表达了当前状态和当前大型模型在实际媒体工作场景中的功能的差异。评论的结果表明Thyi,Iflytek,Wen Xin Yiyan和Tencent Yuanbao一直是RANK在总体列表中首先排名第四,得分超过7,500点。这些大型型号由“大型工厂”支持。相比之下,Doubao,DeepSeek,Kimi和Zhipu Qingyan跑了第五至第八。这三个大型模型的分数相对较低,主要是由于能够汇总长文本的能力,并且在实际审查中无法完全阅读某些提示文件的事实,从而在客观问题上大大减少了标记。通过大型模型的人群,可见工作效率的提高,并且信息的排序已成为功能强大的功能之一。就媒体信息采集功能而言,Wen Xinyi,Thyi和Tencent Yuanbao在前三名中获得了前三名。在评论中,这三个模型不仅可以准确地提供信息,而且还避免了不正确的信息,因此得分越高。相比之下,基米(Kimi),DeepSeek,doubao和Zhipu Qingyan窃取了泥炭搜索结果“很多错误的信息n,得分低。 Text Generation的能力评估了媒体行业“写作”最重要的功能,也是本综述的主要方面之一。视频脚本。排名第二。在审查期间,如果写作结构,开放描述,数据使用,在深度分析和其他方面是完美的和专业的因素。就测量值而言,这篇综述涉及第一次道德酌处权。结果表明,Thyi,Wenxin Yiyan,Dubao和Deepseek得分以上超过1,500分,分别排名第一,至4分,而Tencent Yuanbao排名最后。关于情感关系中“越野”的问题,大多数大型模型都会提醒人们,例如情感操纵,这反映了大型模型具有一定的价值判断。但是,在审查中,腾讯Yuanbao和Wen Xin质疑“偏离”,他们发誓要答案,而低矮的玛丽也被降低了。找到你什么在长期的材料中,对文本的长期审查成为媒体工人的“必要需求”,使大型模型更加知名。 2024年,基米(Kimi)也获得了他的能力,包括长期文字。在电力级的冗长摘要中,Thyi,Wenxin Yiyan和Iflytek排名前三,得分超过1,500。审查发现,大型模型的长期文本受到两个障碍:消耗更多令牌的容量文件越大,成本就越大。因此,对于测试问题“上传两个财务和比较报告”,Deptseek,Kimi和Zhipu Qingyan只能分别上传18%,52%和41.75%的文件,因此得分是莫雷洛的。值得一提的是,在成功上传的两份财务报告中,Talyyi,Iflytek Spark和Tencent Yuanbao不仅可以准确地获得了运营,净利润,毛利润率和其他相关公司的数据,而且还可以获得Tencent的数据Yuanbao使用Hunyuan模型提出了一个比较表,结果很明显。相反,尽管Wen Xinyiyan也形成了一张表,但获得总收入数据存在错误。语言翻译能力一直是大型模型的基准能力,也是在实际应用中使用的最广泛使用的能力。结果表明,Iflytek,Tencent Yuanbao和Thyi在前三名。该分析旨在评估来自五种不同尺寸的实际行业工作情况的大型语言模型产品的性能。总共形成了128个结果。分析方法采用了ELO机制(一种通过数学公式来评估和匹配竞争者的隐藏竞争者的机制),总共有80多名参加评分的法官。评论表明,在媒体行业中应用大型模型的潜力是巨大的,尤其是在获取信息,文本生成和翻译方面。这领先的“大型工厂”模型可以通过资源和技术积累来对综合能力和稳定性有明显的好处。但是,您面临的挑战仍然是严重的,包括识别需要改进的虚假信息以防止误导性分散的能力;长期处理文本的能力和成本问题的限制限于实际价值;道德安全防御线需要继续得到加强,以防止恶意诱发。文本一代的深度和专业精神仍然需要与高级媒体人的水平保持一致。该报告认为,在选择和使用大型模型工具时,媒体从业人员应优先考虑具有稳定的性能,安全可靠的性能的全面头部模型。进行现实验证时,您需要谨慎搜索模型搜索结果,尤其是热门话题或有争议的主题。此外,处理超长文档或CO时需要确认实际模型处理能力,以避免由于容量限制而导致故障。北京新闻壳财务记者WEI BOYA编辑Luo Yidan校对Wang Jinyu Mu Xianglong
上一篇:5连续董事会Hua Hao Energy:公司的劳动和运营活动
下一篇:没有了